pak::pkg_install(
c(
"wbids",
"WDI",
"Teal-Insights/imfweo"
)
)8 Week 4: Import & Tidy Your Data (In-Class)
8.1 Today’s Agenda (90 minutes)
- Understanding Data Integration (20 min)
- Why combine multiple data sources?
- Types of data relationships
- Common integration challenges
- Real examples from loan performance analysis
- Working with Multiple Data Sources (25 min)
- Importing from different sources (CSV, APIs, packages)
- Standardizing country names
- Understanding join types
- Handling missing values
- Integrating Debt Data (40 min)
- Case study: GCDF and IDS data
- Hands-on practice with joins
- Creating richer analysis
- Setting up for capstone project
- Preview: Capstone Project (5 min)
- Next week’s in-person session
- Project options
- Resource sharing
- Team formation
8.2 Learning Objectives
By the end of this session, you will be able to:
- Import data from multiple sources (APIs, CSVs, R packages)
- Standardize key variables for joining datasets
- Combine datasets using different types of joins
- Create integrated analysis incorporating multiple data sources
- Begin exploring capstone project possibilities
Why This Matters for TUFF Analysis
The ability to integrate multiple data sources is crucial for your work:
- Compare TUFF data with official statistics
- Add macroeconomic context to lending data
- Validate data against multiple sources
- Create richer analysis by combining perspectives
Having these skills will help you:
- Work more efficiently
- Find unique insights
- Create compelling visualizations
- Build reproducible workflows
8.3 Today’s Video Lecture
Watch this video lecture to review the concepts from class 4:
8.4 Setup
Let’s get our workspace ready:
# Create a new Quarto document
# File → New File → Quarto Document
# Save as "week_4_integration_in_class.qmd" in your week_4/R folderIntall new packages:
Load required packages:
library(tidyverse) # Core data science tools
library(chinadevfin3) # GCDF 3.0 data
library(imfweo) # IMF WEO data
library(wbids) # WB IDS data
library(countrycode) # Country name standardization
library(WDI) # World Bank Development Indicators
library(janitor) # Data cleaning tools8.5 Understanding Data Integration
8.5.1 Why Combine Data Sources?
In real-world analysis, crucial insights often come from combining different perspectives on the same phenomenon. For example, in analyzing Chinese overseas lending:
- GCDF Data provides:
- Project-level details
- Sectoral breakdown
- Implementation status
- Flow classifications
- IDS Data provides:
- Official debt statistics
- Creditor composition
- Debt service metrics
- Restructuring information
- IMF WEO Data provides:
- Macroeconomic context
- GDP and growth figures
- External sector metrics
- Forward projections
8.5.2 Key Integration Challenges
When combining data, we often face:
- Identifier Mismatches
- Different country names/codes
- Various date formats
- Inconsistent categorizations
- Temporal Alignment
- Different time periods
- Varying frequencies
- Point vs. period data
- Unit Consistency
- Nominal vs. real values
- Currency conversions
- Scale differences
- Conceptual Mapping
- Different definitions
- Varying methodologies
- Classification systems
Let’s see how to handle these challenges systematically.
8.6 Working with Multiple Data Sources
8.6.1 Getting IDS Debt Data
First, let’s get the IDS debt distress data from GitHub:
# URLs for IDS data
ids_data_url <- "https://raw.githubusercontent.com/Teal-Insights/ids_2024_explorations/refs/heads/main/data/ids_debt_distress_data.csv"
ids_metadata_url <- "https://raw.githubusercontent.com/Teal-Insights/ids_2024_explorations/refs/heads/main/data/ids_debt_distress_metadata.csv"
# Import data
ids_data <- read_csv(ids_data_url)Rows: 1241272 Columns: 5
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): geography_id, series_id, counterpart_id
dbl (2): year, value
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.ids_metadata <- read_csv(ids_metadata_url)Rows: 22 Columns: 10
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (9): series_id, event_type, component, creditor, measurement, series_nam...
dbl (1): source_id
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# Look at what we have
glimpse(ids_data)Rows: 1,241,272
Columns: 5
$ geography_id <chr> "AFG", "AFG", "AFG", "AFG", "AFG", "AFG", "AFG", "AFG",…
$ series_id <chr> "DT.DXR.DPPG.CD", "DT.NFL.DECT.CD", "DT.NFL.DECT.CD", "…
$ counterpart_id <chr> "915", "915", "915", "915", "915", "915", "915", "915",…
$ year <dbl> 2014, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2…
$ value <dbl> 0, 66174000, 94274000, 50937000, 73861000, 64935000, 42…glimpse(ids_metadata)Rows: 22
Columns: 10
$ series_id <chr> "DT.IXA.DPPG.CD.CG", "DT.IXA.OFFT.CD", "DT.IXA.PRV…
$ event_type <chr> "arrears", "arrears", "arrears", "arrears", "arrea…
$ component <chr> "interest", "interest", "interest", "principal", "…
$ creditor <chr> "all", "official", "private", "official", "private…
$ measurement <chr> "flow", "flow", "flow", "flow", "flow", "flow", "f…
$ series_name <chr> "Net change in interest arrears (current US$)", "I…
$ source_id <dbl> 81, 81, 81, 81, 81, 81, 81, 81, 81, 81, 81, 81, 81…
$ source_name <chr> "International Debt Statistics: DSSI", "Internatio…
$ source_note <chr> "Net change in interest arrears is the variation i…
$ source_organization <chr> "World Bank, International Debt Statistics.", "Wor…8.6.2 Getting IMF WEO Data
Now let’s add some macroeconomic context:
# List available WEO series
weo_list_series()# A tibble: 44 × 3
series_code series_name units
<chr> <chr> <chr>
1 BCA Current account balance U.S. dollars
2 BCA_NGDPD Current account balance Percent of GDP
3 GGR General government revenue National curren…
4 GGR_NGDP General government revenue Percent of GDP
5 GGSB General government structural balance National curren…
6 GGSB_NPGDP General government structural balance Percent of pote…
7 GGX General government total expenditure National curren…
8 GGXCNL General government net lending/borrowing National curren…
9 GGXCNL_NGDP General government net lending/borrowing Percent of GDP
10 GGXONLB General government primary net lending/borrowing National curren…
# ℹ 34 more rows# Get GDP data for all countries
gdp_data <- weo_get(
series = c(
"NGDPD", # Nominal GDP in USD
"NGDP_RPCH" # Real GDP growth
),
# Get all countries - we'll filter later
countries = weo_list_countries()$country_code,
start_year = 2000
)ℹ Available series: NGDP_R, NGDP_RPCH, NGDP, NGDPD, PPPGDP, NGDP_D, NGDPRPC, NGDPRPPPPC, NGDPPC, NGDPDPC, PPPPC, PPPSH, PPPEX, NID_NGDP, NGSD_NGDP, PCPI, PCPIPCH, PCPIE, PCPIEPCH, TM_RPCH, TMG_RPCH, TX_RPCH, TXG_RPCH, LP, GGR, GGR_NGDP, GGX, GGX_NGDP, GGXCNL, GGXCNL_NGDP, GGXONLB, GGXONLB_NGDP, GGXWDG, GGXWDG_NGDP, NGDP_FY, BCA, BCA_NGDPD, LUR, GGXWDN, GGXWDN_NGDP, LE, GGSB, GGSB_NPGDP, NGAP_NPGDPℹ Requested series: NGDPD, NGDP_RPCHℹ Filtered series: NGDPD, NGDP_RPCHglimpse(gdp_data)Rows: 11,567
Columns: 7
$ country_name <chr> "Aruba", "Aruba", "Aruba", "Aruba", "Aruba", "Aruba", "Ar…
$ country_code <chr> "ABW", "ABW", "ABW", "ABW", "ABW", "ABW", "ABW", "ABW", "…
$ series_name <chr> "Gross domestic product, current prices", "Gross domestic…
$ units <chr> "U.S. dollars", "U.S. dollars", "U.S. dollars", "U.S. dol…
$ series_code <chr> "NGDPD", "NGDPD", "NGDPD", "NGDPD", "NGDPD", "NGDPD", "NG…
$ year <int> 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 200…
$ value <dbl> 1.873, 1.896, 1.962, 2.044, 2.255, 2.360, 2.470, 2.678, 2…8.6.3 Understanding Join Types
Before we combine our data, let’s understand the four main types of joins:
- Inner Join: Keep only rows that match in both datasets
# Example with small datasets
country_debt <- tibble(
country = c("Angola", "Ghana", "Kenya"),
debt_stock = c(100, 200, 300)
)
country_debt# A tibble: 3 × 2
country debt_stock
<chr> <dbl>
1 Angola 100
2 Ghana 200
3 Kenya 300country_gdp <- tibble(
country = c("Angola", "Ghana", "Zambia"),
gdp = c(1000, 2000, 3000)
)
country_gdp# A tibble: 3 × 2
country gdp
<chr> <dbl>
1 Angola 1000
2 Ghana 2000
3 Zambia 3000# Inner join - only Angola and Ghana appear
country_debt |>
inner_join(country_gdp, by = "country")# A tibble: 2 × 3
country debt_stock gdp
<chr> <dbl> <dbl>
1 Angola 100 1000
2 Ghana 200 2000- Left Join: Keep all rows from left dataset, match where possible from right
# Left join - Kenya appears with NA for gdp
country_debt |>
left_join(country_gdp, by = "country")# A tibble: 3 × 3
country debt_stock gdp
<chr> <dbl> <dbl>
1 Angola 100 1000
2 Ghana 200 2000
3 Kenya 300 NA- Right Join: Keep all rows from right dataset, match where possible from left
# Right join - Zambia appears with NA for debt_stock
country_debt |>
right_join(country_gdp, by = "country")# A tibble: 3 × 3
country debt_stock gdp
<chr> <dbl> <dbl>
1 Angola 100 1000
2 Ghana 200 2000
3 Zambia NA 3000- Full Join: Keep all rows from both datasets
# Full join - all countries appear, with NAs where no match
country_debt |>
full_join(country_gdp, by = "country")# A tibble: 4 × 3
country debt_stock gdp
<chr> <dbl> <dbl>
1 Angola 100 1000
2 Ghana 200 2000
3 Kenya 300 NA
4 Zambia NA 3000
Choosing Join Types
- Use
inner_join()when you only want complete cases - Use
left_join()to keep all your primary data - Use
right_join()rarely (just use left_join with datasets reversed) - Use
full_join()to see what might be missing
8.6.4 Practice Exercise: Basic Joins
Let’s practice with some GCDF data:
# Get total commitments by country
country_totals <- get_gcdf3_dataset() |>
filter(recommended_for_aggregates == "Yes") |>
group_by(country_name,iso3c) |>
summarize(
total_commitments = sum(amount_constant_usd_2021, na.rm = TRUE)
) |>
ungroup()`summarise()` has grouped output by 'country_name'. You can override using the
`.groups` argument.country_totals# A tibble: 153 × 3
country_name iso3c total_commitments
<chr> <chr> <dbl>
1 Afghanistan AFG 587689317.
2 Africa, regional <NA> 5507076256.
3 Albania ALB 128497599.
4 Algeria DZA 310574109.
5 America, regional <NA> 410036891.
6 Angola AGO 65104946269.
7 Antigua & Barbuda ATG 534626006.
8 Argentina ARG 138750987557.
9 Armenia ARM 105655950.
10 Asia, regional <NA> 518936052.
# ℹ 143 more rows# Get GDP data for comparison
gdp_totals <- gdp_data |>
filter(
series_code == "NGDPD", # Nominal GDP
year == 2021 # Latest year
) |>
select(country_code, gdp = value)
gdp_totals# A tibble: 194 × 2
country_code gdp
<chr> <dbl>
1 ABW 3.10
2 AFG 14.3
3 AGO 84.4
4 ALB 18.0
5 AND 3.32
6 ARE 415.
7 ARG 486.
8 ARM 13.9
9 ATG 1.60
10 AUS 1658.
# ℹ 184 more rowsYour turn: Try different joins
Inner join - which countries have both commitment and GDP data?
Left join - keep all countries with GCDF commitments
Full join - see which countries are missing from each source
Joining by a common key
What variable in each dataset is the same? Look at the documentation (e.g. run ?left_join()) to figure out how to connect the two datasets.
8.7 Integrating Debt Data
Now let’s work with our real analysis datasets:
8.7.1 Step 1: Standardize Country Information
First, we need consistent country identifiers:
# Standardize IDS data
ids_clean <- ids_data |>
mutate(
# Add ISO3C codes
iso3c = countrycode(
sourcevar = geography_id,
origin = "iso3c",
destination = "iso3c"
),
# Add standardized names
country_name = countrycode(
sourcevar = iso3c,
origin = "iso3c",
destination = "country.name"
)
)Warning: There was 1 warning in `mutate()`.
ℹ In argument: `iso3c = countrycode(sourcevar = geography_id, origin = "iso3c",
destination = "iso3c")`.
Caused by warning:
! Some values were not matched unambiguously: EAP, ECA, IDA, IDX, LAC, LDC, LIC, LMC, LMY, MIC, MNA, SAS, SSA, UMC, XKXids_clean |> glimpse()Rows: 1,241,272
Columns: 7
$ geography_id <chr> "AFG", "AFG", "AFG", "AFG", "AFG", "AFG", "AFG", "AFG",…
$ series_id <chr> "DT.DXR.DPPG.CD", "DT.NFL.DECT.CD", "DT.NFL.DECT.CD", "…
$ counterpart_id <chr> "915", "915", "915", "915", "915", "915", "915", "915",…
$ year <dbl> 2014, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2…
$ value <dbl> 0, 66174000, 94274000, 50937000, 73861000, 64935000, 42…
$ iso3c <chr> "AFG", "AFG", "AFG", "AFG", "AFG", "AFG", "AFG", "AFG",…
$ country_name <chr> "Afghanistan", "Afghanistan", "Afghanistan", "Afghanist…# Standardize WEO data
weo_clean <- gdp_data |>
mutate(
# Add ISO3C codes - WEO uses ISO3C already
iso3c = country_code,
# Add standardized names
country_name = countrycode(
sourcevar = iso3c,
origin = "iso3c",
destination = "country.name"
)
)Warning: There was 1 warning in `mutate()`.
ℹ In argument: `country_name = countrycode(sourcevar = iso3c, origin = "iso3c",
destination = "country.name")`.
Caused by warning:
! Some values were not matched unambiguously: UVK, WBGweo_clean |> glimpse()Rows: 11,567
Columns: 8
$ country_name <chr> "Aruba", "Aruba", "Aruba", "Aruba", "Aruba", "Aruba", "Ar…
$ country_code <chr> "ABW", "ABW", "ABW", "ABW", "ABW", "ABW", "ABW", "ABW", "…
$ series_name <chr> "Gross domestic product, current prices", "Gross domestic…
$ units <chr> "U.S. dollars", "U.S. dollars", "U.S. dollars", "U.S. dol…
$ series_code <chr> "NGDPD", "NGDPD", "NGDPD", "NGDPD", "NGDPD", "NGDPD", "NG…
$ year <int> 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 200…
$ value <dbl> 1.873, 1.896, 1.962, 2.044, 2.255, 2.360, 2.470, 2.678, 2…
$ iso3c <chr> "ABW", "ABW", "ABW", "ABW", "ABW", "ABW", "ABW", "ABW", "…8.7.2 Step 2: Focus on Key Variables
Let’s look at debt rescheduling:
# Get rescheduling data from IDS
rescheduling <- ids_clean |>
filter(
# Total amount rescheduled
series_id == "DT.TXR.DPPG.CD",
# Only Chinese debt
counterpart_id == "730",
# Focus on recent years
year >= 2015
)
# Get GCDF rescheduling cases and identify DSSI cases
gcdf_rescheduling <- get_gcdf3_dataset() |>
filter(
flow_type == "Debt rescheduling",
recommended_for_aggregates == "Yes"
) |>
mutate(
is_dssi = str_detect(description, "DSSI")
)
# Look at the mix of DSSI vs other reschedulings
gcdf_rescheduling |>
count(is_dssi)# A tibble: 2 × 2
is_dssi n
<lgl> <int>
1 FALSE 127
2 TRUE 768.7.3 Step 3: Create Combined Analysis
Now we can start comparing sources:
# Get GCDF rescheduling counts by country-year
gcdf_counts <- gcdf_rescheduling |>
group_by(country_name, commitment_year, is_dssi) |>
summarize(
rescheduling_count = n(),
.groups = "drop"
) |>
# Make counts by type
pivot_wider(
names_from = is_dssi,
values_from = rescheduling_count,
values_fill = 0,
names_prefix = "gcdf_count_"
)
# Combine with IDS amounts
rescheduling_comparison <- gcdf_counts |>
distinct() |>
left_join(
rescheduling |>
distinct(
country_name,
year,
ids_amount = value
),
by = c(
"country_name" = "country_name",
"commitment_year" = "year"
)
)
# Check the results
rescheduling_comparison |>
filter(!is.na(ids_amount)) |>
filter(commitment_year >= 2015) |>
arrange(desc(ids_amount))# A tibble: 45 × 5
country_name commitment_year gcdf_count_FALSE gcdf_count_TRUE ids_amount
<chr> <dbl> <int> <int> <dbl>
1 Angola 2021 1 1 706480000
2 Angola 2020 2 1 417506000
3 Zambia 2021 0 1 396636083.
4 Congo - Brazzavi… 2018 1 0 348614000
5 Kenya 2021 0 4 260013515.
6 Pakistan 2020 0 15 211145714.
7 Congo - Brazzavi… 2021 0 4 172200897.
8 Zambia 2020 1 1 136449665.
9 Cameroon 2021 0 1 93865480.
10 Tanzania 2021 0 1 91867983.
# ℹ 35 more rows# First create summary data
rescheduling_summary <- gcdf_rescheduling |>
# Get annual counts by DSSI vs non-DSSI
group_by(commitment_year, is_dssi) |>
summarize(
count = n(),
.groups = "drop"
) |>
# Make DSSI labels more readable
mutate(
rescheduling_type = if_else(
is_dssi,
"DSSI Rescheduling",
"Other Rescheduling"
)
)
# Create visualization
ggplot(
rescheduling_summary |>
filter(commitment_year >= 2015)
) +
geom_col(
aes(
x = commitment_year,
y = count,
fill = rescheduling_type
),
position = "stack"
) +
scale_fill_brewer(palette = "Set2") +
labs(
title = "Debt Rescheduling Cases by Type",
subtitle = "DSSI vs Other Reschedulings (2015-2021)",
x = "Year",
y = "Number of Cases",
fill = NULL
) +
theme_minimal()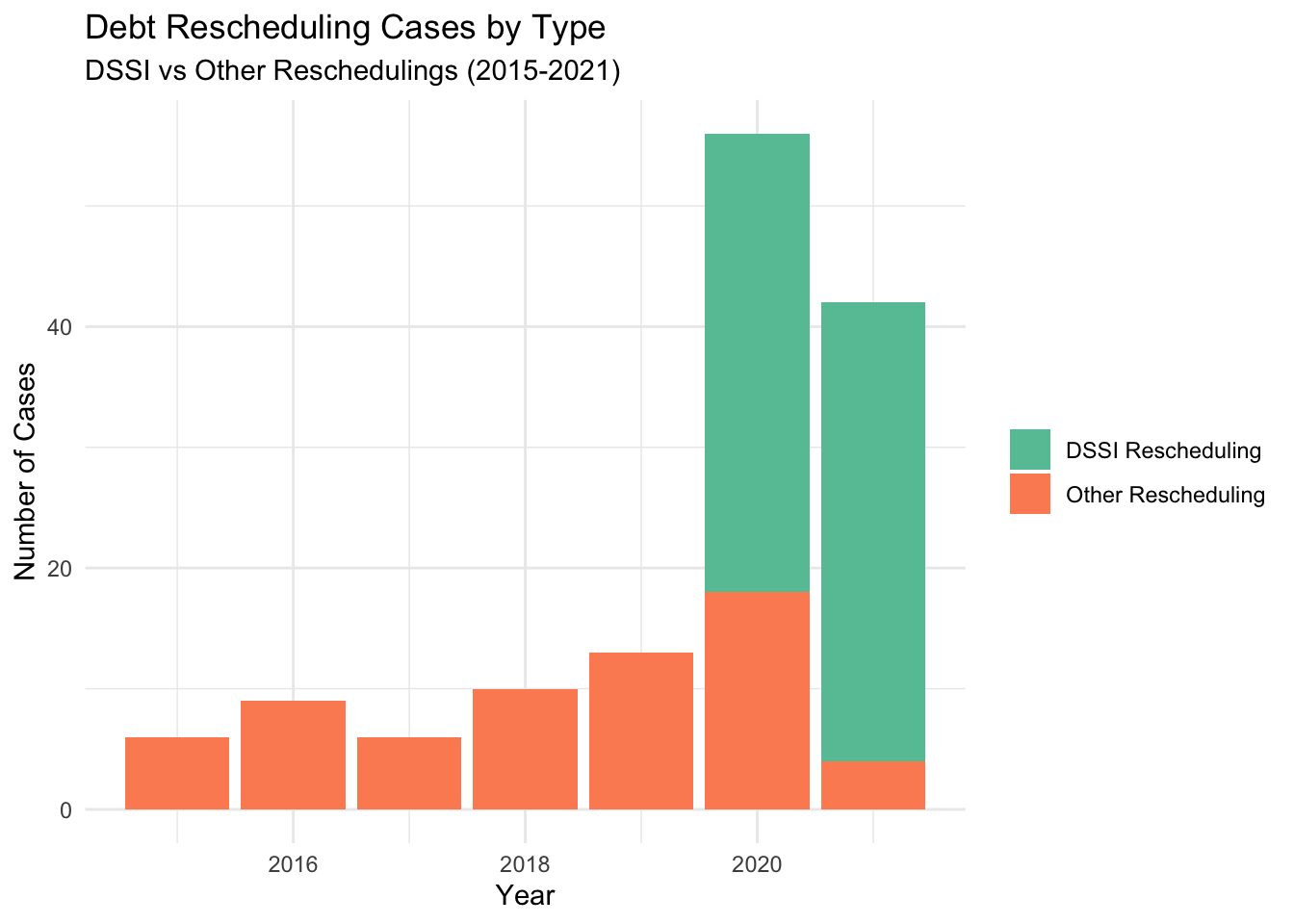
8.7.4 Practice Exercise: Exploring Rescheduling Patterns
Your turn! Try these exercises:
- Analyze DSSI participation:
- Which countries had DSSI reschedulings?
- How does this compare to eligible countries?
- What patterns do you see by region?
- Compare with IDS reporting:
- Do countries with more GCDF reschedulings show larger IDS amounts?
- Are there systematic differences by region or income group?
- What might explain any discrepancies?
- Add economic context:
- Use WEO data to add GDP context
- Calculate rescheduling amounts as % of GDP
- Look for patterns in timing relative to growth rates
Analysis Tips
- Start by looking at simple counts and patterns
- Add complexity gradually
- Document unexpected findings
- Consider what patterns might mean for data collection
8.8 Setting Up the Capstone Project
8.8.1 Project Structure
The capstone project will explore Chinese overseas lending data using multiple sources:
- Core Data Sources
- GCDF 3.0 Database
- World Bank IDS
- IMF WEO
- Other sources you identify
- Key Questions
- How do GCDF and IDS data compare?
- What patterns emerge in debt distress?
- How does economic context matter?
- What stories deserve deeper investigation?
- Output Options
- Blog post
- Policy brief
- Interactive dashboard
- Automated report system
- Your creative ideas!
8.8.2 Next Week’s Schedule
Morning Session (9:30-11:00) - Storytelling with Data workshop - Project planning - Team formation
Midday (11:30-3:00) - Optional work session - One-on-one consultations - Team collaboration time
Afternoon Session (3:00-4:30) - Project development - Peer feedback - Planning next steps
8.8.3 This Week’s Preparation
- Explore the Data
- Try different integration approaches
- Look for interesting patterns
- Document questions that arise
- Consider Output Format
- What would be most useful?
- Who is your audience?
- What story do you want to tell?
- Optional: Other Projects
- If you have other data to work with
- Different questions to explore
- Alternative output formats
8.9 Resources for Data Integration
8.9.1 Essential References
- R for Data Science Chapters
- Notable Data Resources
8.9.2 Additional Learning
- Data Integration Concepts
8.10 Wrapping Up
8.10.1 Key Takeaways
- Data Integration Power
- Combining sources reveals new insights
- Standardization is crucial
- Documentation matters
- Join Mechanics
- Different joins for different needs
- Always check results
- Consider what missing data means
- Project Preparation
- Start exploring now
- Think about storytelling
- Consider your audience
8.10.2 Next Steps
- This Week
- Explore the data
- Try different combinations
- Document interesting findings
- Next Wednesday
- Bring your discoveries
- Come with questions
- Be ready to collaborate
Remember: The goal is to create something useful for your work while practicing your new R skills!